


☆
1

Comments:
Very nice overview of deep learning!
### Why layers are important?
Why not using some input neurons, some output neurons and some arbitrary graph between/connecting them? For instance a clique or an Erdos-Renyi random graph?
### Gradient descent:
ReLu "$f(x)=max(0,x)$" seems to be the most popular activation function. It is also a very simple/basic function. Is it possible to design an optimization method (other than backpropagation using stochastic gradient descent) dedicated to neural networks having only ReLu neurons?

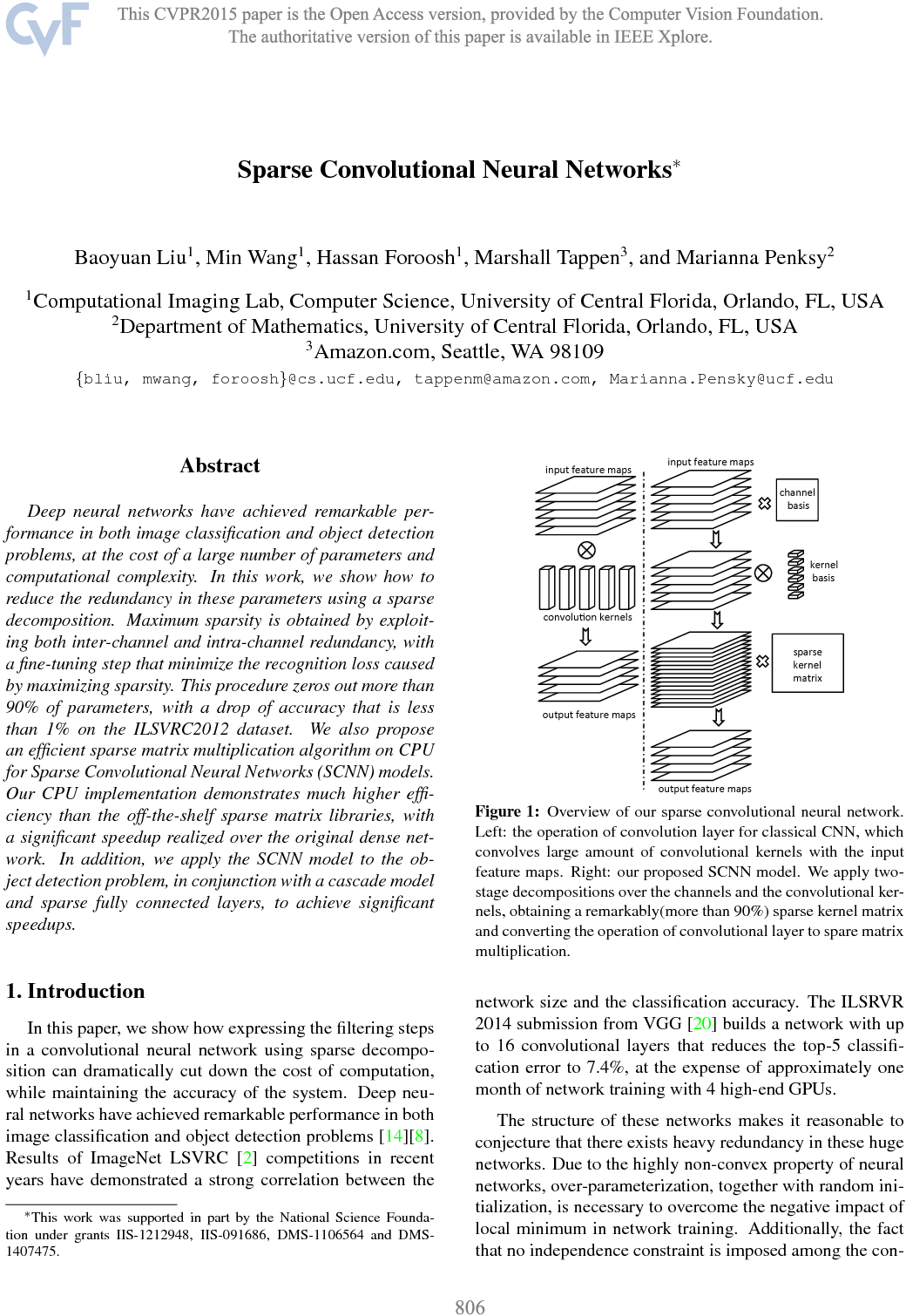

Comments: