




☆
1

Comments:
### Concerns:
- It seems that the method needs to store $L$ integers per node. That is a total of $N*L$ integers while storing the graph requires $2*M$ integers (where $M$ is the number of edges), thus the method is useful only if $L<2*M/N$ (that is if $L$ smaller than the average degree). In the experiments, the average degree of the three graphs is approximately 7, 55 and 42, while $L$ is 50 or 80. There is thus no gain in space compared to a good implementation of a straightforward algorithm storing the full graph.
- Once the sketch for each node is obtained, it is not clear how to obtain each relevant pair of nodes and its similarity. It seems that each possible pair of nodes has to be considered which is very under-optimal and not scalable.
- Each graph used in the experiments easily fits in the RAM of any commodity machine. For such small graphs, an exact method storing the full graph should be faster in practice.
### Alternative approach:
https://github.com/maxdan94/NeighSim
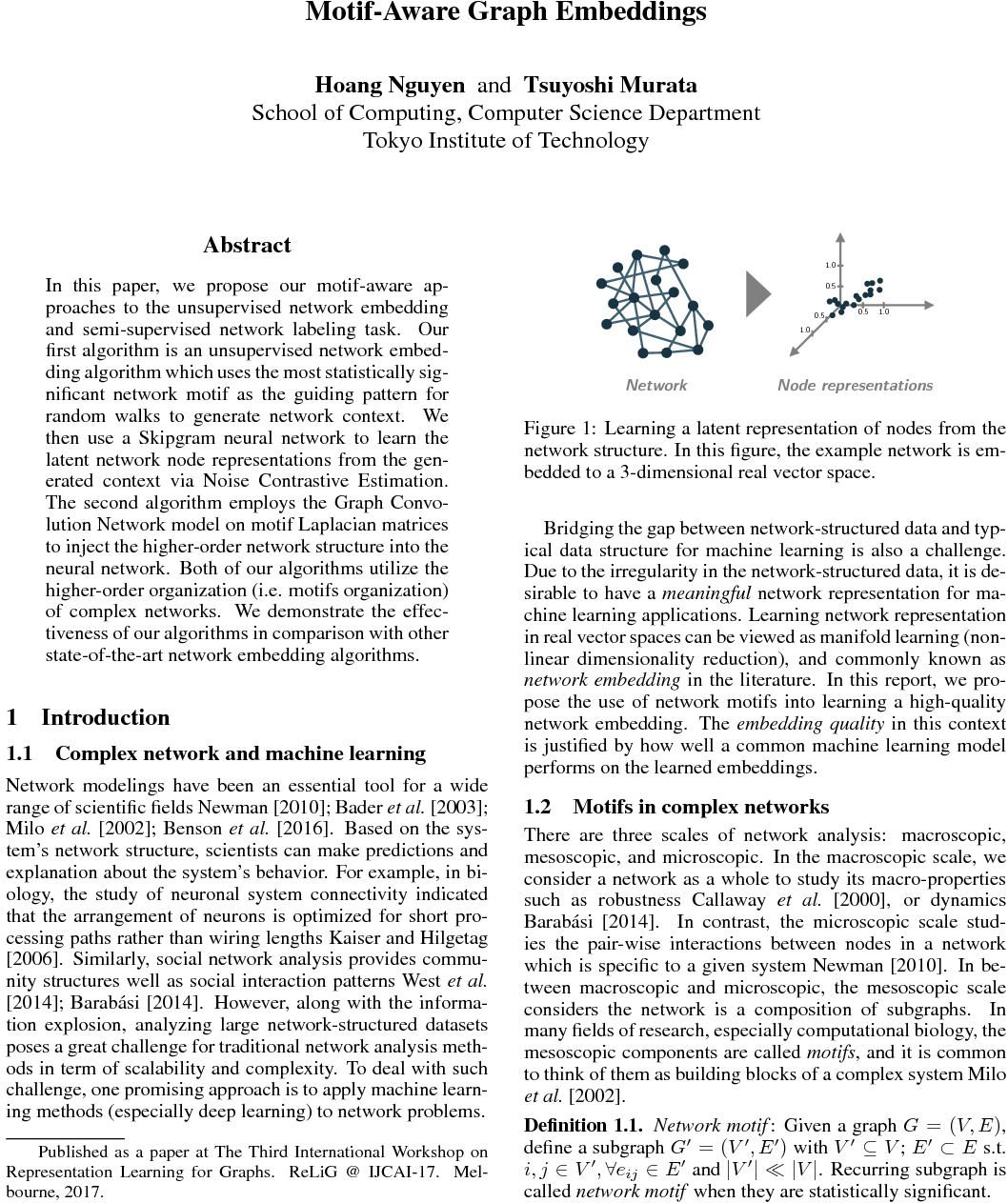
Comments: