

☆
1
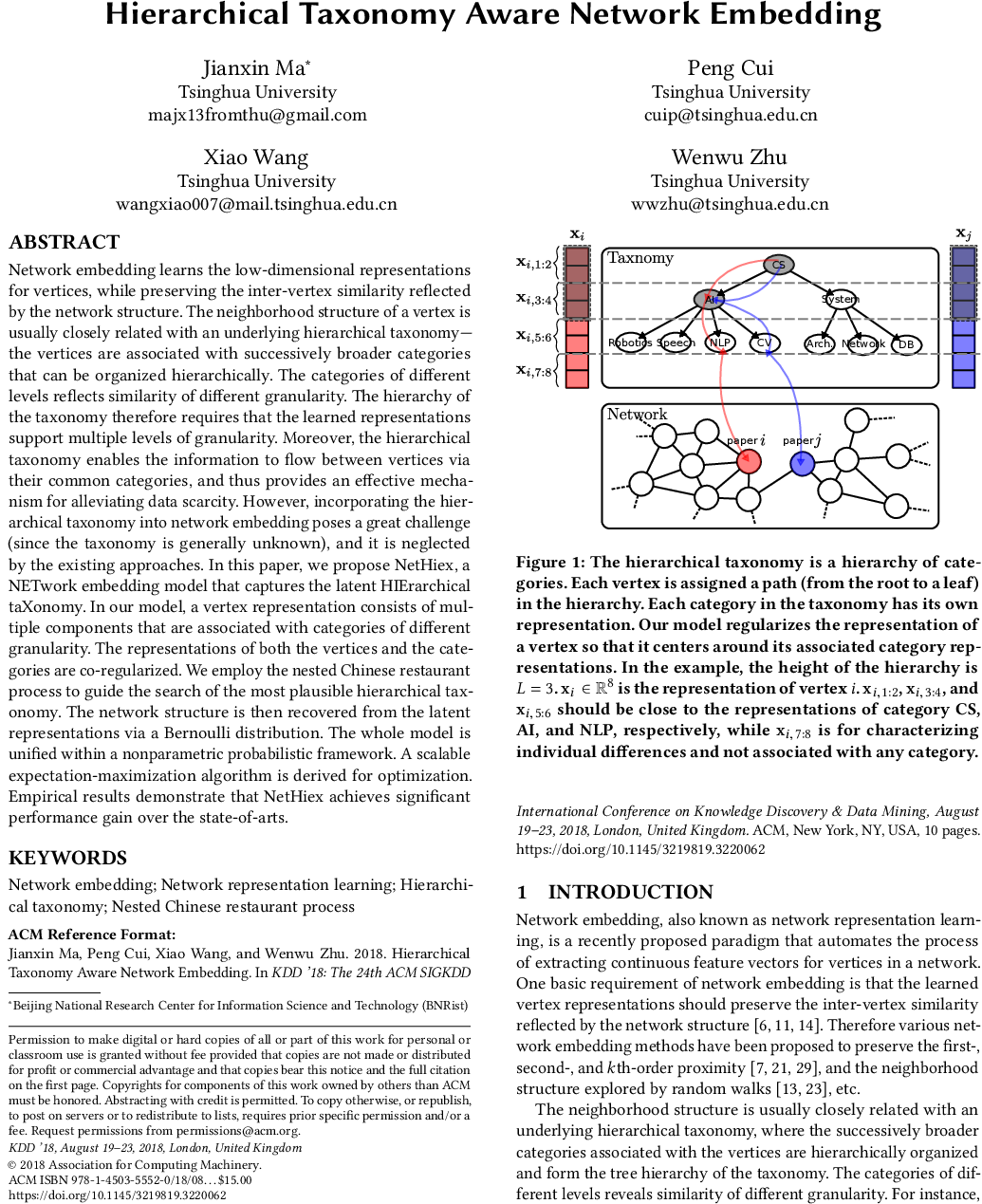
Authors:
Peng Cui,
Jianxin Ma,
Xiao Wang and Wenwu Zhu
Liked by: Maximimi
Domains: network embedding
Tags: KDD2018, hierarchical representation, social networks
Liked by: Maximimi
Domains: network embedding
Tags: KDD2018, hierarchical representation, social networks
Uploaded by:
Ayan Kumar Bhowmick
Upload date: 2018-11-06 10:46:26
Edited at: 2018-11-07 10:30:05
Edited by: Maximimi
Upload date: 2018-11-06 10:46:26
Edited at: 2018-11-07 10:30:05
Edited by: Maximimi
Comments:
Edited by Maximimi at 2018-11-07 10:42:33